Aujourd’hui, beaucoup d’entreprises choisissent Ruby on Rails pour programmer leur solution en interne. Les avantages d’utiliser Ruby on Rails sont sa rapidité à développer une solution proprement, et la réactivité de la grande communauté qui l’utilise aujourd’hui. Encore récemment, de grandes compagnies comme Github ou Twitter utilisaient Ruby on Rails comme solution back-end. À ce jour, ces deux compagnies couplent leurs installations Ruby on Rails avec Erlang et/ou Scala, à cause principalement du manque de performances (plus spécifiquement de la latence) des requêtes HTTP.
Dans cet article, nous vous proposons l’exploration d’un nouveau framework web, basé sur les performances et la rapidité de réponse par requête : Phoenix.
Sur la base de cette suite d’articles, nous avons décidé de développer une petite application web en Phoenix, et de la déployer publiquement sur Internet via Heroku, une plateforme de déploiement d’applications web reconnue pour sa facilité d’utilisation.
Ce premier article traitera du développement d’une simple application web en
Phoenix, une to do liste. La to do liste est l’une des premières applications de base développée pour l’apprentissage d’un framework web. Ici, votre humble serviteur a découvert Elixir avant de jouer avec Phoenix. Ce sera donc l’occasion pour moi de vous montrer tout ce que j’ai pu découvrir dans ce framework, notamment les avantages et les inconvénients, lors du développement et déploiement de l’application web sur Heroku.
Pré-requis
Qu’est-ce que Phoenix?
Phoenix est un framework web écrit en Elixir, un jeune langage de programmation principalement écrit et maintenu par José Valim, tournant sur la machine virtuelle d’Erlang. Elixir se veut facile à s’adapter à un changement d’ordre de grandeur de la demande (scalable en anglais), tolérant aux pannes, extensible et compatible avec toute bibliothèque Erlang. Le grand avantage de Elixir par rapport à Erlang est sa syntaxe, qui se veut plus claire. Phoenix est un framework web qui se veut simple dans sa prise en main, productif dans la manière de développer et maintenir ses applications, rapide et tolérant aux fautes. La première version stable de Phoenix est sortie en Août 2015, et est déjà utilisée en production par plusieurs entreprises. Sa popularité est telle qu’une conférence lui a été personnellement donnée lors de la dernière Elixir Conf, notamment pour discuter des nouveaux points de la prochaine version du framework.
Ce framework implémente le pattern MVC (pour Modèle-Vue-Contrôleur) côté serveur. Ce pattern est reconnu et utilisé dans de populaires frameworks web comme Django ou encore Ruby on Rails. Un grand nombre de compagnies
comme ProcessOne, Pinterest ou encore FranceTV utilisent aujourd’hui Elixir et Phoenix en production, et font connaître leur joie d’utiliser cette technologie.
Un autre avantage de Phoenix, adressé pour les développeurs Ruby on Rails, est que le framework ressemble au framework web Ruby, ce qui en fait un outil facile à prendre en main par un développeur ou une équipe de développeurs Ruby on Rails.
Pour quoi faire ?
Chez DernierCri, nous nous intéressons fortement aux nouvelles technologies et nous sommes toujours prêts à explorer leurs fonctionnalités dans le but d’améliorer nos talents et de rendre plus confortable l’utilisation des applications que nous développons. Nous pensons que Elixir et Phoenix seront des technologies incontournables dans les prochaines années. Cet article est ainsi l’occasion de pouvoir jouer avec ces derniers, mais aussi de pouvoir imaginer ce qu’il pourra être possible de faire avec ce framework, en interne.
À la fin de cette partie, vous devriez pouvoir lancer localement votre application Phoenix sur une base de données PostgreSQL, et gérer facilement vos to do sur la page d’accueil.
Installation
Pour commencer, je vais considérer que vous avez installé sur votre machine
Elixir, Phoenix, et correctement configurer PostgreSQL. Nous utiliserons les versions 19 de la VM Erlang, 1.3.3 de Elixir, et 1.2 de Phoenix. Si vous ne l’avez pas encore fait, je vous invite à prendre connaissances des trois liens qui vous permettront de parfaire ces installations :
Enfin, si vous souhaitez reproduire toute notre mise-en-oeuvre, merci de vous
assurer que les versions associées aux outils utilisés sont les suivantes :
- version 19 de la VM d’Erlang (`elixir — version`),
- version 1.3.3 de Elixir (`elixir — version`),
- version 1.2 de Phonix (`mix phoenix.new -v`).
Création d’une _to do_ liste
Lancement de Phoenix
Afin de pouvoir créer et interagir avec notre application Phoenix, nous allons
utiliser Mix, un simple manager de projets. Pour découvrir les commandes associées à Mix, vous pouvez taper `mix help`.
Le chemin qui contiendra notre application sera `~/dev/todos/`.
Nous créons une application Phoenix avec `mix phoenix.new ~/dev/todos/`.
Le résultat est la génération, dans le répertoire `~/dev/todos/`, de tous les
fichiers associés au lancement l’application Phoenix :
Plusieurs fichiers et répertoires sont intéressants ici :
- `mix.exs` contient toutes les dépendances associées à/aux application(s)développée(s),
- `mix.lock` contient toutes les informations issues des dépendances ajoutéesdans `mix.exs`,
- `config/` contient toutes les informations nécessaires à la bonne configuration et au bon déploiement de l’application,
- `web/` contient le code de l’application : les vues, les modèles et lescontrôleurs (ce que nous modifierons principalement).
Phoenix tourne par défaut avec la base de données PostgreSQL. La configuration de la base de données se trouve dans `config/dev.exs`, mais nous ne l’utiliserons pas dans cette première partie. Afin de pouvoir faire tourner notre application, nous allons créer notre base de données associée à notre application : `mix ecto.create`.
Une fois la base créée, vous pouvez lancer le serveur Phoenix afin de faire
tourner l’application: `mix phoenix.server`. Si vous n’avez pas spécifier explicitement le port d’écoute, Phoenix devrait vous indiquer que vous pouvez alors vous connecter sur l’adresse `localhost:4000` via votre navigateur, afin de visualiser la page d’accueil du framework.
Le répertoire `web`
Ce répertoire est le coeur de l’application. Contrairement à Django qui permet que chaque application ait un répertoire propre afin de faciliter l’exportation et l’intégration d’applications pour différents sites, Phoenix ne le propose pas encore. Par contre, la version 1.3 du framework apportera bien son lot de nouveautés, comme la différenciation des applications dans un répertoire.
Il contient :
À part `channels`, `gettext.ex` et `web.ex`, nous allons explorer et nous servir de tous les autres répertoires et fichiers contenus dans ce répertoire :
- `controllers` est le répertoire contenant les modules Elixir qui, eux-mêmes,contiendront les actions invoquées par le `router`, en réponse aux requêtes HTTP envoyées depuis votre navigateur internet — ces actions pourront retourner du texte, du code HTML, un rendu de page web ou encore une structure de données type JSON,
- `models` contient toutes les structures de données associées aux données de l’application, comme les informations issues des utilisateurs de votre application, leurs articles dans le cas d’un blog, ou encore les prochains to do,
- `static` contient toutes les données statiques de l’application web comme lecode CSS, JavaScript ou encore les images à associer au site internet (nous appelons ça les _assets_),
- `templates`, qui va contenir les templates HTML de vos vues,
- `views` qui contiendra… vos vues, c’est-à-dire l’identité, ou l’aspect visuel, devotre application,
- `router.ex`, un fichier Elixir qui va pouvoir contenir les associations route/action de votre application.
Pour mieux appréhender la suite, je vais détailler ce que fait et peut faire le
routage.
Le but du routage est d’associer des requêtes HTTP avec les actions des contrôleurs. Ce mécanisme est extrêmement fort car il permet de faire ici ces associations en temps réel, et de définir des séries de transformation sur les routes.
Pour donner un exemple de routage, imaginons que vous déployez une application de planning de rendez-vous (`planning.com`) qui contient 2 entités : User et Rdv. Ces deux entités peuvent être créer, consulter, modifier et supprimer (concept du CRUD). Sur votre application, vous pourrez alors avoir les chemins suivants :
- `planning.com/user/new` qui appellera l’action `create_user` dans le contrôleur `UserController`,
- `planning.com/user/delete/id` qui appellera l’action `delete_user`, donné par`id` dans le contrôleur `UserController`,
- `planning.com/rdv/id` qui appellera l’action `consult_rdv`, donné par `id` dans le contrôleur `RdvController`,
- etc…
Pour une application qui étend le CRUD, on pourra alors avoir les chemins ci-dessous :
Simplement, les routes qui étendent les huit clauses d’un CRUD sont appelées resources.
Ainsi, les huit lignes ci-dessus pourront être raccourcies en deux petites lignes :
Aussi, la restriction des routes pour une application pourra être spécifiée
via deux options : `:only` et `:except`.
Ainsi, `resources “/users”, UserController, except: [:delete]` voudra spécifier que toutes les actions du CRUD pour `User` sont acceptées, sauf celui de supprimer une entité `User`.
Pour finir, toutes les routes des applications sont à spécifier dans `router.ex`.
Malheureusement, cette mise en avant des routes dans un seul fichier est désavantageuse car, en ayant plusieurs contrôleurs, le nombre de routes va s’alourdir et la compréhension du code sera plus difficile. Heureusement, ce problème sera pallié avec la version 1.3 du framework.
Notre _to do_ app
L’application aura le comportement défini suivant :
- lors de son lancement, nous tomberons directement sur la liste de toutes les tâches à faire,
- nous pourrons créer directement une tâche à faire via l’interface, sur la page d’accueil,
- la tâche détiendra comme attributs un titre, un corps qui pourra contenir ounon de plus amples informations, ainsi qu’une date limite pour terminer celle-ci,
- le corps de la tâche et la date limite de celle-ci seront considérés commeoptionnels pour l’utilisateur, et seront définis par défaut respectivement à la chaîne nulle et à la date du jour de la création de la tâche,
- de même, il sera possible de visualiser et de supprimer la tâche via la paged’accueil.
Phoenix possède un mécanisme très simple afin de pouvoir générer extrêmement facilement une ressource. Ce mécanisme est associé à `phoenix.gen.html`, qui va pouvoir générer la ressource demandée avec les champs demandés.
Dans le cas de notre _to do_ liste, nous souhaitons avoir une ressource `Todo` qui contienne un titre (`title`) de type `string`, un corps (`body`) de type `string`, et une date limite (`due_date`) de type `datetime`: `mix phoenix.gen.html Todo todos title:string body:string due_date:datetime`.
Il faut savoir que cette commande est une commande magique. Phoenix créera pour nous le contrôleur (`todo_controller.ex`), le modèle (`todo.ex`), des templates (`templates/todo/`) et la vue (`todo_view.ex`). La seule chose que Phoenix ne fait pas pour nous est de créer le chemin jusqu’au contrôleur `TodoController`, ce qu’il faudra ajouter dans `router.ex` en ajoutant ces 2 lignes de code :
Dans ce tutoriel, nous utilisons Ecto, un DSL (Domain Specific Language) pour interagir avec les bases de données dans le langage Elixir. Ecto est écrit en Elixir, et est un outil complet pour travailler sur des bases de données relationnelles.
Comme écrit dans nos comportements, nous voulons que l’utilisateur puisse seulement inscrire le titre de la to do, et non pas les 3 champs. En effet, il faut savoir que Phoenix considère que les 3 champs (`title`, `body` et `due_date`) sont requis explicitement lors de la création de la to do. Le simple fait de permettre à l’utilisateur d’utiliser des champs par défaut se fera directement dans le modèle de l’application, dans notre cas `models/todo.ex`.
Voici le code par défaut, généré par défaut par Phoenix, de notre modèle :
Ce module appartient comme on le voit à notre application `Todo`, qui contient les 3 champs requis.
Une fonction est présente dans ce module : `changeset`. Les fonctions `changeset`, en Phoenix, permettent de créer et/ou de modifier les modèles de données de l’application. Ainsi, au lieu d’effectuer et de jouer avec les validations à l’intérieur du modèle, Phoenix délègue cette passe aux _changesets_ de Ecto ainsi que les contraintes. Ecto va ainsi séparer l’accès à la base de données, la génération des requêtes et la validation des modèles dans 3 modules séparés.
Ces validations seront effectuées avant toute opération sur la base de données, et donc n’a pas besoin d’interagir avec celle-ci.
Par exemple, imaginons que nous voulons faire le traitement suivant sur nos données dans `changeset`:
Ici, nous allons récupérer les informations issues dans `params`, et décomposer cette structure en des valeurs distinctes dans `cast`, puis valider les données recueillies (“la longueur du titre est-elle comprise entre 3 et 80 caractères ?”) afin de pouvoir interroger la base de données sur le fait que nous voulons une contrainte unique sur le titre de la tâche.
Ainsi, Ecto va toujours valider les données avant les contraintes, afin de ne pas faire de requêtes inutiles sur la base de données de l’application. Avec les `changesets`, vous pourrez envoyer la structure requise de votre modèle (`struct`) et les paramètres qui se trouvent être les informations transmises via la requête HTTP (`params`). Ainsi, pour transmettre des données concernant `Todo`, dans l’état présent, voici le code associé :
`changeset(%Todo{}, [name: “…”, body: “…”, due_date: …]`.
Ce qui nous intéresse ici est de seulement passer dans la requête `title`, et de mettre par défaut les champs `body` et `due_date` respectivement à “My title is explicit…” et à date et l’heure de création de la tâche.
Aussi, pour complexifier un peu notre travail, nous voulons que le champ `title` soit de longueur minimale de 5 caractères, et de longueur maximale de 80 caractères.
Heureusement, rien n’est impossible avec Phoenix, tout est très simple à faire, et toutes nos modifications seront exclusives à la fonction `changeset` !
La fonction `validate_required` permet de connaître par avance les champs explicités par l’utilisateur de l’application, pour créer la structure associée.
Ainsi, en supprimant `:body` et `:due_date` du corps de la fonction, nous ne demandons plus explicitement que le champ `title` à l’utilisateur. Pour valider la longueur du champ `title` pris en paramètre, il faudra ajouter dans la cascade de fonctions associées à `struct` la fonction `validate_length`.
Cette fonction prend en paramètre le champ à valider, ainsi que la longueur minimale et maximale de la valeur associée au champ (ici, 5 et 80).
Enfin, nous voulons spécifier les champs non-requis explicitement par l’utilisateur. Pour cela, nous modifions directement les paramètres pris en compte dans la définition de la fonction, en ajoutant les valeurs par défaut.
Au final, notre fonction `changeset` prend donc en compte toutes les demandes explicitées dans la définition du comportement global de notre application Phoenix :
Étant donné que nous venons d’ajouter des éléments dans notre base de données, nous devons migrer cette base via : `mix ecto.migrate`. Une fois la migration effectuée, nous pouvons lancer notre serveur, nous connecter via notre navigateur, en local, sur le port 4000 et… tomber sur une page (presque) vide, qui pourra lister toutes nos tâches.
Après le back-end, le front…
Le reste: un petit travail sur le CSS afin de pouvoir rendre le tout “joli” pour un déploiement sur un serveur public !
La prochaine étape est de déployer notre application sur le web, afin de pouvoir y accéder partout sans avoir nécessairement notre ordinateur sous la main.
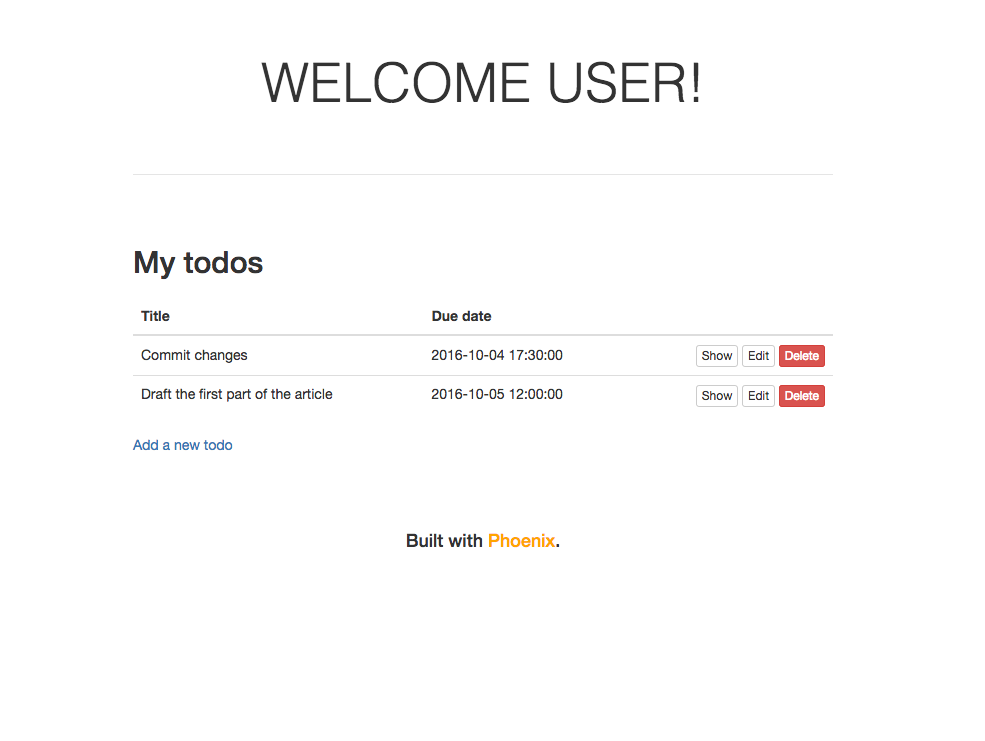
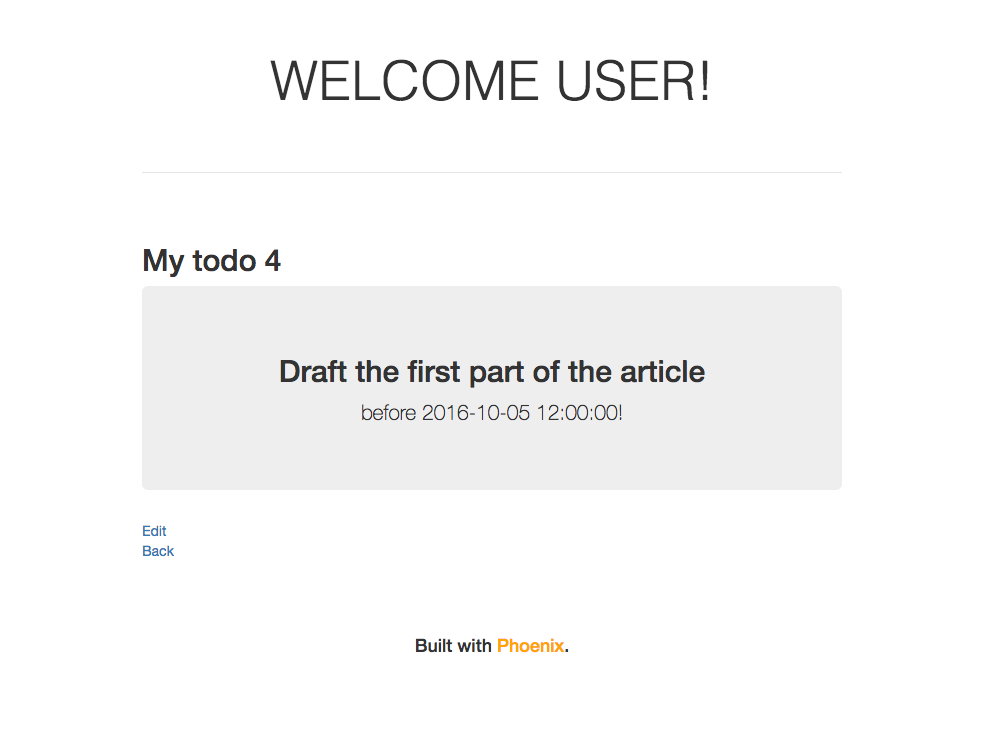
Déploiement sur Heroku de l’app Phoenix
Création de l’application Heroku
Ajout des _buildpacks_
Chaque buildpack applicatif (Node, Ruby, Elixir…) contient un script permettant le lancement de l’application (script release dans les sources du projet). Il est possible de surcharger ce script en lançant de nouvelles procédures, via le fichier `Procfile`.
Nous créerons notre application Heroku en lui indiquant d’ores-et-déjà d’installer le buildpack Elixir:
`heroku create — buildpack “https://github.com/HashNuke/heroku-buildpack-elixir.git"`
Cette commande nous donnera en sortie l’URL correspondant à l’application créée sur Heroku. Par exemple, sur notre machine locale, cette commande nous répondra ceci:
Ainsi, dans cet exemple, le nom de notre application est `radiant-bastion-51881` , et l’URL de l’application Heroku est disponible juste en dessous. Si vous cliquez sur le lien pointant vers votre application, vous tomberez alors sur la page suivante:
De même, il faudra installer un nouveau buildpack, nécessaire au fonctionnement de Phoenix:
`heroku buildpacks:add https://github.com/gjaldon/heroku-buildpack-phoenix-static.git`.
Il est important de savoir qu’une application se construit graduellement !
Ainsi, ce sera le dernier buildpack installé qui sera lancé.
Il est maintenant possible de créer une nouvelle remote au projet versioné de notre application, via `heroku git:remote -a radiant-bastion-51881`.
L’ajout de cette dernière nous permettra plus tard de pousser sur le serveur les fichiers de notre application.
L’application Heroku nous répondra en nous explicitant les deux _buildpacks_ installés :
- 1. https://github.com/HashNuke/heroku-buildpack-elixir.git
- 2. https://github.com/gjaldon/heroku-buildpack-phoenix-static.git
Ajout et installation du fichier de configuration
Après avoir expliciter l’installation des buildpacks pour Elixir et Phoenix, il faudra installer un fichier de configuration Elixir. Ce fichier de configuration est nécessaire au bon fonctionnement de notre application, et sera nommé (par convention) `elixir_buildpack.config`. Voici son contenu :
Ce fichier de configuration explicite d’abord la version d’Erlang et d’Elixir à utiliser. On explicitera aussi certaines informations comme le fait qu’il ne faut pas reconstruire le projet de zéro à chaque fois, qu’elle est la variable contenant l’URL permettant d’accéder à notre base de données, ou le chemin de l’application à lancer. `DATABASE_URL` est, quant à elle, une variable de configuration qui sera exportée à la compilation.
Le buildpack est Phoenix est, quant à lui, exporté avec un fichier de configuration par défaut qu’il ne sera pas nécessaire de modifier pour le bon fonctionnement de l’application Heroku.
Modification de la configuration de l’application à déployer
Notre application Phoenix contient des informations sensibles à ne pas déployer sur un serveur (autant sur un serveur git que sur un serveur Heroku). Ces informations sont stockées dans le fichier `config/prod.secret.exs`, qui sera à intégrer dans une règle d’ignorance (dans le fichier `.gitignore` du projet).
Étant donné que Heroku utilise des variables d’environnement pour passer des informations sensibles, nous devons alors modifier notre configuration dans le but de la déployer.
Premièrement, nous allons nous assurer que la clef secrète permettant de communiquer et d’exécuter des informations sur notre application soit chargée par des variables d’environnement au lieu du fichier secret explicité plus haut. Pour celà, nous allons nous occuper de modifier le fichier `config/prod.exs` en ajoutant, après `cache_static_manifest: “priv/static/manifest.json”`, cette ligne :
`secret_key_base: System.get_env(“SECRET_KEY_BASE”)`
et le petit pavé de code suivant :
Ce pavé permettra de configurer la base de données de notre application Phoenix, en explicitant le fait que Ecto devra communiquer avec une base de données PostgreSQL, que l’URL de cette base se trouvera dans la variable globale `DATABASE_URL`, que le nombre de connexions entrantes sur notre app est de 10 par défaut (nombre utilisé si la variable d’environnement `POOL_SIZE` ne l’explicite pas), et que l’on active `ssl` sur l’application (donc le transfert de données chiffrées).
Maintenant que la configuration de la base est faite, il faut expliciter le fait que Phoenix doit utiliser l’URL de notre application Heroku, et forcer l’utilisation de SSL.
À la place de `url: [host: “example.com”, port: 80]`, remplacez-la par :
Maintenant, tout est terminé, et il ne reste plus qu’à supprimer le lien vers le fichier qui contient ces informations sensibles : `import_config “prod.secret.exs”`.
Création du fichier `Procfile`
Comme énoncé précédemment, le fichier `Procfile` va permettre de surcharger le script de lancement de l’application `Phoenix`. Ici, nous allons simplement expliciter que l’environnement de production est… la production, et que le lancement de l’application web se fera via `mix phoenix.server`. Voici le contenu du fichier `Procfile` :
`web: MIX_ENV=prod mix phoenix.server`
Heroku Ready
Merci de vérifier que Heroku Postgres add-on a bien été installé sur votre application !
Création de la base de données
Pour déployer finalement notre application sur Heroku, il faut surcharger les variables d’environnement. La variable de configuration `DATABASE_URL` est automatiquement créée par Heroku. Cependant, il faut créer la base de données : `heroku addons:create heroku-postgresql:hobby-dev`.
Initialisation du nombre de connexions entrantes
Étant donné que notre base de données `hobby-dev` permet 20 connexions simultanées, nous allons configurer cette dernière à 18.
`heroku config:set POOL_SIZE=18`
Initialisation de la clef secrète
`mix phoenix.gen.secret`
Cette commande nous renverra une nouvelle clef qu’il faudra ajouter comme variable `SECRET_KEY_BASE`.
Par exemple, dans notre cas:
Déploiement
Après avoir fait toutes ces configurations, il est maintenant temps de déployer le tout sur Heroku !
Heroku va compiler tous les fichiers, et nous donnera une réponse comme celle-ci :
Il faut maintenant créer et migrer les tables sur l’application :
Enfin, un simple `heroku open` nous ouvrira notre navigateur préféré pour nous afficher notre belle `to do` liste !
Mission reussie!
Pour utiliser notre application test, c’est par ici.
Quelques liens intéressants pour poursuivre la lecture:
- Elixir — official website
- Elixir — Wikipedia webpage
- Phoenix — official website
- Elixir and Phoenix: The Future of Web APIs and Apps?
- What I learned migrating a Rails app to Elixir and Phoenix
- What is a changeset in Phoenix/Elixir?
- Why I wouldn’t use rails for a new company
- Elm, Elixir and Phoenix in production, at France TV